In this lesson we will focus on dealing with multi-labelled images. In the prior edition of Walk with fastai this was done using the high level API, however in the spirit of revisited we will be doing so with the mid-level API and will continue to use it throughout the rest of this course.
This will be a vision problem so again we will import the vision library:
from fastai.vision.allimport*
/home/zach/miniconda3/envs/fastai/lib/python3.9/site-packages/tqdm/auto.py:22: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Below are the exact imports from what we are using today:
The labels are located in the "all_tags" column, and we can extract the raw values as a regular array using the .values attribute
all_labels = []for row in all_tags: all_labels += row.split(" ")
Since each row’s tags are split by a space, we can turn this string into an array and add these values directly into our all_labels array. This will be a giant list that has many repeated values on purpose.
In total there are 2899 labels, but this doesn’t tell us how many different labels there are. Let’s find out:
counts = { label: all_labels.count(label) for label in different_labels}counts = { key: value for key, value insorted( counts.items(), key =lambda item: -item[1] )}
counts = { label: all_labels.count(label) for label in different_labels}counts = { key: value for key, value insorted( counts.items(), key =lambda item: -item[1] )}
label: all_labels.count(label)
Python lists contain a method called count which can take in an item and count how many times it occurs in the list.
counts = { key: value for key, value insorted( counts.items(), key =lambda item: -item[1] )}
To make our lives easier, we can sort the list by the number of instances found.
key =lambda item: -item[1]
To make the dictionary be sorted from highest to lowest occurences, we sort by the negative of the actual value
What we find is that selective_logging, artisinal_mine, slash_burn, conventional_mine, and blow_down had the least number of occurances. For the sake of todays lesson we will get rid of rows with these values.
Typically a Data Scientist has two choices when it comes to dealing with rare values, either leaving them in as they are or performing oversampling. We’re dropping them for convience but normally one would want to oversample the training dataset for rare values and ensure the validation dataset has a few instances of them to test on.
Next we’ll use some pandas magic to filter our dataframe by these values:
for key, count in counts.items():if count <10: df = df[df["tags"].str.contains(key) ==False]
for key, count in counts.items():if count <10: df = df[df["tags"].str.contains(key) ==False]
if count <10:
Since we’re limiting it based on rare values, we’ll arbitrarily get rid of classes that occur less than 10 times
df['tags'].str
This converts each rows item into a string and we can utilize methods inside the str class to be applied on every single row
.contains(key) ==False
From here we then look for if any of these rows have our rare class, and only keep the ones that do not.
len(df)
968
Despite what seemed like getting rid of quite a lot of classes, they only showed up in < 40 rows. In the real world one would want to try and get more data from these underrepresented classes if possible, or perform oversampling on them.
x: Our x’s are colored images, meaning we should use PILImage
y: Our y’s are multilabeled images, meaning we should use MultiCategorize
We need to write a set of getters to get each one based on looking at a single row of data
x: Our x’s are located at src/'train'/{fname}.jpg, so this can be written as a function that looks at the image_name column
y: Our y’s are a split string based on the tags column, and this too can be written as a function
Why as functions?
Technically these can be written as lambda functions, such as lambda x: print(x) however lambda’s are not pickleable, meaning if you export the Learner it will give you an error of something along the lines of "Cannot pickle lambda ...". The solution is to define them as seperate functions that you pull in somewhere before importing the Learner
There is no set value for what is “train” or “validation”, so we can randomly split the dataset again
Now that we’ve seen how these are written, in fastai there exists a labeller we can use instead called the ColReader which takes in the index of the column and any adjustments we want to make:
We need to explicitly pass in the list of different class labels to use here.
OneHotEncode(len(different_labels))
For our particular problem, just doing MultiCategorize isn’t quite enough, we also need to do OneHotEncode. This is because MultiCategorize will just turn our labels into something like 17, 22 (the index’s into the vocab), we need to turn it into [0, 0, ...1, ...1, ...0] where each 1 represents a label present in the image. But to do so we must pass in the number of different labels present.
The RandomSplitter can accept a validation percentage as well as a random seed to be set during the splitting. After instantiating the class we can then pass in any items we want to have split, such as our dataframe here.
We now return the PILImage expected as well as our one-hot encoded labels!
show_at(dsets.train, 0);
Building some DataLoaders
Lastly we need to build some DataLoaders. The fastaiDatasets class has a .dataloaders() function for us to do so easily, we just need to pass in some transforms to use:
You may notice that we don’t pass any Resize or other augmentation to the item transforms, just ToTensor. This is because all of the images are already 256x256, so there isn’t a need to and we can just jump to augmenting the data on the GPU.
Let’s look at a batch of data to make sure everything looks correct:
dls.show_batch()
Great! Now to train a model
Training a Model
Similar to our previous problem, we will use the baseline resnet34 for this task, and since we are looking at multiple labels we will want to use the accuracy_multi metric:
We can see that the head of our model is still exactly the same, since we have a total of 17 classes that can show up. So what needs to change for our multi-label problem?
learn.loss_func
FlattenedLoss of BCEWithLogitsLoss()
The loss function.
The difference between normal Cross Entropy and Binary Cross Entropy with Logits is rather than performing a softmax, we instead perform what is called a sigmoid operation and use nn.BCEWithLogitsLoss instead of nn.CrossEntropyLoss:
t = tensor([[0.1, 0.5, 0.3, 0.7, 0.2]])torch.sigmoid(t)
After scaling we can then also limit what is perceved as “seen” vs “not seen” through a threshold:
learn.loss_func.thresh
0.5
This essentially means that if there are any results that are less than 0.5 from the output of our sigmoid then we ignore them and assume they are not there.
Keeping the thresholds aligned!
It’s extremely important to remember the metric and loss function’s thresholds should be the exact same otherwise you’re looking at two different versions of the same result. E.g. while you can just change the metric’s threshold to be 0.6, the loss function will still be 0.5 so you’re not actually training with the assumption that the right answer should be > 0.6
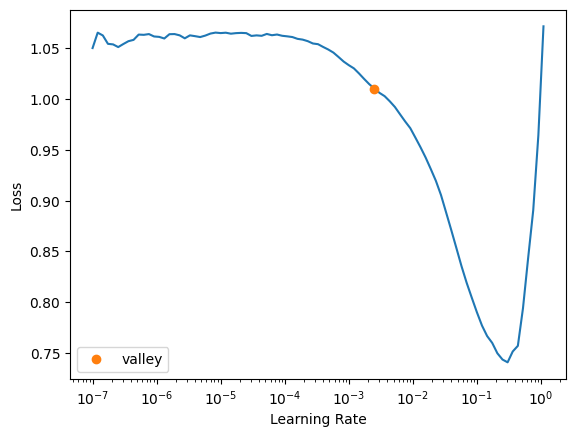
Now that we have everything setup, let’s find a learning rate and train!
learn.lr_find()
SuggestedLRs(valley=0.002511886414140463)
We find that 2e-3 is a pretty good learning rate, so let’s do some fine tuning!
This lr/2.6**4 is a general rule of thumb that Jeremy Howard found works quite well when doing gradual unfreezing, see the ULMFiT notebook to see it in practice!
And now let’s look at our results:
learn.show_results(figsize=(15,15))
Predictions in the wild
While we’ve looked at how to train, let’s look at how to predict and get back our answers without using the fastai API.
First we need the mean and standard deviation of ImageNet
vector = [1]*4vector[1] =-1
Then we create a vector of how these two sets of three numbers should be formatted so that a matrix multiplication between the image and the setting can be performed
mean = tensor(mean).view(*vector)std = tensor(std).view(*vector)
Finally we apply these two formats to the tensors and return them
I highly recommend Lesson 1 from Deep Learning from the Foundations to learn more about this!
The compress function creates an iterator that filters elements based on some boolean array, which is what our decoded_preds are originally. We can use this to find what labels are actually present!
present_labels
['partly_cloudy', 'primary']
And now we’ve successfully done what fastai does during predictions end-to-end: