from fastai.vision.all import *Lesson Video:
Introduction
In the previous lesson we saw how the fastai API is built and applied it to classify Cats and Dogs as well as on a real Kaggle dataset. In this lesson we’re going to go back to some Machine Learning basics and use the lowest-level API of fastai to train a hand-written digit classifier!
As this is a vision problem, we will import the vision library:
Working with the data
The dataset for today is the MNIST handwritten digits dataset. It contains digits written from 0 -> 9 on an image.
Let’s download the data:
path = untar_data(URLs.MNIST); path, path.ls()
100.03% [15687680/15683414 00:00<00:00]
(Path('/home/jovyan/.fastai/data/mnist_png'),
(#2) [Path('/home/jovyan/.fastai/data/mnist_png/testing'),Path('/home/jovyan/.fastai/data/mnist_png/training')])We can see it downloaded it to a folder called mnist_png and has two folders, training and testing. Let’s grab all the images from these directories:
items = get_image_files(path)
items[:10](#10) [Path('/home/jovyan/.fastai/data/mnist_png/testing/7/4199.png'),Path('/home/jovyan/.fastai/data/mnist_png/testing/7/6662.png'),Path('/home/jovyan/.fastai/data/mnist_png/testing/7/7320.png'),Path('/home/jovyan/.fastai/data/mnist_png/testing/7/5914.png'),Path('/home/jovyan/.fastai/data/mnist_png/testing/7/5422.png'),Path('/home/jovyan/.fastai/data/mnist_png/testing/7/7544.png'),Path('/home/jovyan/.fastai/data/mnist_png/testing/7/3743.png'),Path('/home/jovyan/.fastai/data/mnist_png/testing/7/383.png'),Path('/home/jovyan/.fastai/data/mnist_png/testing/7/9015.png'),Path('/home/jovyan/.fastai/data/mnist_png/testing/7/2565.png')]We actually call get_image_files this time, and it brings us all of the images in both the testing/ and training/ folders.
Next we need to try opening an image. Last time we used PIL.Image directly, this time we will use the fastai API:
im = PILImageBW.create(items[0])im = PILImageBW.create(items[0])PILImageThis is the main image class that handles opening the image and setting it up to be used in the fastai data framework
PILImageBWWe have a black and white image (two channel), so we need to open it through the black and white specific PILImage class
.createThis is the class constructor that will create a new PILImageBW object from whatever is passed in
im.show()<AxesSubplot: >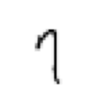
im.show()<AxesSubplot: >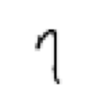
showWe want to visually plot the data to the screen, and most of the lowest level data API’s contain a show functionality to do so
Next we need to figure out how to split the dataset. Since our data is split by testing and training folders, the GrandparentSplitter is the one we want:
splitter = GrandparentSplitter(
train_name="training",
valid_name="testing",
)splitter = GrandparentSplitter(
train_name="training",
valid_name="testing",
) train_name="training",
valid_name="testing",This splitter works by passing in the folder for the training dataset and the test dataset, and we assume that it’s possible to extract the labels from them seperately (as splits and labelling are two seperate stages)
As the name implies, splitters are designed to be applied to some list of data so let’s do that:
splits = splitter(items)
splits[0][:5], splits[1][:5]([10000, 10001, 10002, 10003, 10004], [0, 1, 2, 3, 4])splits[0] correlates to our training dataset and splits[1] correlates to our validation set. If you write a custom splitter or splits technically you can have n split datasets!
len(splits[0]), len(splits[1])(60000, 10000)We can see the train dataset has 60,000 items and our validation has 10,000
The next step is to build a Datasets object. This is fastai’s equivalent to a torch.data.Dataset object and handles seperating out items into different lists, creating said dataset based on the inputs passed in, and so forth.
dsrc = Datasets(
items,
tfms=[[PILImageBW.create], [parent_label, Categorize]],
splits=splits
)dsrc = Datasets(
items,
tfms=[[PILImageBW.create], [parent_label, Categorize]],
splits=splits
)DatasetsThe datasets object needs to take in some items that count as our dataset, how to open them, and how to split them
tfmsThese are directions on transforms to be applied to each object that is returned from one item.
PILImageBW.createWe saw this earlier, this shows how to create our x’s
[parent_label, Categorize]This is how we label our data (or the y). parent_label looks at the parent folder for the name, and Categorize will perform label encoding.
splits = splitsFinally these are our splits generated earlier based on the GrandparentSplitter
Transforms get passed in as a list of lists, with each inner list meaning the x or the y. So we could have something like so for two image inputs: tfms = [[PILImageBW.create, PILImageBW.create], [parent_label, Categorize]] (though our items would need to reflect this).
To take a look at an item in the dataset, fastai has a function called show_at which takes an datasource and an index and tries to view it:
show_at(dsrc.train, 3);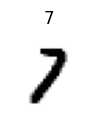
show_at(dsrc.train, 3);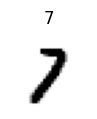
dsrc.trainThe training dataset
3The fourth item in the dataset
We can see that the data is a number 7 with a label of 7. Next we need to transform the data into something we can train on. Remember the role of item transforms were to get the image to the same size, and we also need to turn this data into a PyTorch tensor.
The transforms to do so are:
item_tfms = [CropPad(34), RandomCrop(size=28), ToTensor()]item_tfms = [CropPad(34), RandomCrop(size=28), ToTensor()]CropPad(34)This will either crop or pad the image to a particular size
RandomCrop(size=28)This will randomly take a 28x28 pixel chunk of the image and crop to that
ToTensor()This is what will convert our PILImage into a TensorImage
As they are item transforms, these will be cpu bound.
Now that the data is all the same size, we can perform the batch transforms, which should convert the data into a float tensor (to be computationally efficient) and normalize the data:
batch_tfms = [IntToFloatTensor(), Normalize()]batch_tfms = [IntToFloatTensor(), Normalize()]IntToFloatTensorThis will convert tensors from integers to floats
NormalizeThis will perform normalization on the data and make training a bit faster
When we call Normalize without giving it any statistics, it will base the normalization values on the first batch of data in the dataset. This has generally been found to give a very good approximiation of the full dataset’s values
And the last step is to turn them into a set of training and validation dataloaders by passing in all of our information. Since the data is so small we can use a larger batch size:
dls = dsrc.dataloaders(
bs=128,
after_item=item_tfms,
after_batch=batch_tfms
)
About
after_item and after_batch
When outside the DataBlock API, item_tfms and batch_tfms will always be referenced as after_item and after_batch, including inside the dataloader itself.
Then we can show a batch of data with augmentations performed:
dls.show_batch()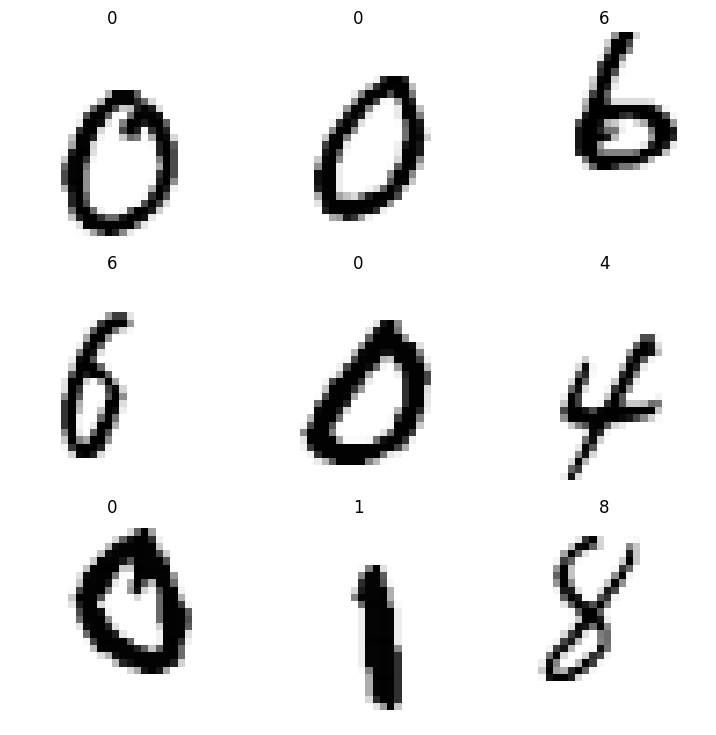
From here we can get the raw values from a single batch of data through the one_batch function:
xb, yb = dls.one_batch()xb, yb = dls.one_batch()xbxb denotes a batch of the x’s (inputs)
ybyb denotes a batch of the y’s (labels)
We can view the shapes of the data:
xb.shape, yb.shape(torch.Size([128, 1, 28, 28]), torch.Size([128]))Remember a torch tensor is an array of some shape. So our x’s are 128 different arrays of shape 28x28 pixels, and our y’s are a single array of 128 numbers
Lastly we can see that fastai was able to automatically calculate the number of different y’s we had (classes) in the training dataset and throws them into an attribute called c:
dls.c10The dataset also had this, try running dsrc.c
In summary:
- We take in inputs that are images of [1 x 28 x 28] and we stack 128 of them together
- Our output is an array of 128 single numbers
- We somehow take these numbers and align them with one of ten classes
Building a Model and Training!
Next we’ll follow what we did in the previous lesson and grab a model to use. For this particular problem we’ll use a resnet18 architecture and fastai’s vision_learner. We won’t use a pretrained model however this time!
Why should we not use a pretrained model?
First, we used a different normalization schema earlier rather than .from_stats. Second, think about it. Are handwritten digits the same as ImageNet in any way? Not really. So it’s better to use a completely random model here for this small problem.
model = resnet18( num_classes=dls.c).cuda(); model.fcLinear(in_features=512, out_features=10, bias=True)This changed our outputs to be the number of classes, but is this enough?
model(xb)RuntimeError: Given groups=1, weight of size [64, 3, 7, 7], expected input[128, 1, 28, 28] to have 3 channels, but got 1 channels insteadBasically what this error tells us is the first layer of the model is expecting a three channel image, and we gave it a single channel instead. Which makes perfect sense! Let’s look at that first layer to see what it looks like:
model.conv1Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)In order for our model to work well, we need a Conv2d layer that can work on single channel images, but is roughly the same size. We can achieve this by just reducing that 3 to 1:
model.conv1 = nn.Conv2d(
in_channels=1,
out_channels=64,
kernel_size=(7,7),
stride=(2,2),
padding=(3,3),
bias=False
)And now we can see it works!
model.cuda();model(xb)TensorImageBW([[ 0.8653, -0.5842, -0.0095, ..., -0.4335, -0.5770, -0.3396],
[ 1.0708, -0.5977, -0.6581, ..., 0.8838, -0.1800, 0.0831],
[ 0.8686, 0.7356, 0.1484, ..., -0.7021, 0.5971, -0.2051],
...,
[ 0.4341, -0.5231, -0.3952, ..., -0.4436, -0.9311, 0.6171],
[ 0.0964, 0.0140, -1.6474, ..., -0.5224, -1.1066, 0.5010],
[-0.0789, 0.3279, -0.2987, ..., -0.3033, -0.7143, -0.5016]],
device='cuda:0', grad_fn=<AliasBackward0>)
What if we used a pretrained model?
If we used a pretrained model here, it is possible to utilize the old pretrained weights. We can do so by averaging each channel’s weights and having the single channel’s weights be the result:
model.conv1.weight.mean(dim=1).unsqueeze(1)We would find this would give a weight equal to shape [64, 1, 7, 7], the size of our new Conv2D layer
All that’s left is to build a Learner (the base class of what we used last lesson) and train!
learn = Learner(dls, model, metrics=[accuracy])learn.fit(1)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.122788 | 0.153307 | 0.953300 | 00:09 |
Great! We successfully built a model that can classify handwritten digits! We can predict on one of them using fastai’s predict method:
items[0]Path('/home/jovyan/.fastai/data/mnist_png/testing/7/4199.png')preds = learn.predict(items[0]); preds('7',
tensor(7),
tensor([6.1501e-04, 7.0428e-02, 3.8973e-03, 2.9338e-03, 3.8078e-03, 1.0854e-03,
3.5933e-05, 8.9145e-01, 4.3205e-03, 2.1431e-02]))preds = learn.predict(items[0]); preds('7',
tensor(7),
tensor([6.1501e-04, 7.0428e-02, 3.8973e-03, 2.9338e-03, 3.8078e-03, 1.0854e-03,
3.5933e-05, 8.9145e-01, 4.3205e-03, 2.1431e-02]))'7'This seven is the string representation of the class, found in dls.vocab.
tensor(7)This is the argmax (or what index had the highest value) of the predictions, and it is then used as the index into dls.vocab
tensor([6.1501e-04, 7.0428e-02, 3.8973e-03, ...]))These are the softmax (or taking all the outputs and making them sum to one) probabilities for each class. The argmax is the highest value from here
To recreate what we just did without learn.predict it would look something like so:
dl = learn.dls.test_dl(items[:1])
inps, preds, _, decoded_preds = learn.get_preds(dl=dl, with_decoded=True, with_input=True)
image, class_prediction = learn.dls.decode_batch((inps,) + tuplify(decoded_preds))[0]dl = learn.dls.test_dl(items[:1])
inps, preds, _, decoded_preds = learn.get_preds(dl=dl, with_decoded=True, with_input=True)
image, class_prediction = learn.dls.decode_batch((inps,) + tuplify(decoded_preds))[0]dl = learn.dls.test_dl(items[: 1])fastai will create a test data loader based on the validation transforms. It takes in a list of items, so we can quickly create a list of 1
inps, preds, _, decoded_preds = learn.get_preds(dl=dl, with_decoded=True, with_input=True)Passing in with_input=True will return the passed input to the model not decoded in any way
image, class_prediction = learn.dls.decode_batch((inps,) + tuplify(decoded_preds))[0]To fully decode a batch of data (or a set of input and output) through fastai’s data transforms, we can call dls.decode_batch which takes in a tuple of inputs and decoded predictions (try running the (inps,) + tuplify(decoded_preds) yourself to see what it does behavior wise!)
class_prediction, decoded_preds('7', tensor([7]))And finally to do it with just fastai transforms:
learn.dls.after_item, learn.dls.after_batch(Pipeline: CropPad -- {'size': (34, 34), 'pad_mode': 'zeros'} -> RandomCrop -- {'size': (28, 28), 'p': 1.0} -> ToTensor,
Pipeline: IntToFloatTensor -- {'div': 255.0, 'div_mask': 1} -> Normalize -- {'mean': None, 'std': None, 'axes': (0, 2, 3)})learn.dls.after_batch[1].mean, learn.dls.after_batch[1].std(TensorImageBW([[[[0.1302]]]], device='cuda:0'),
TensorImageBW([[[[0.3081]]]], device='cuda:0'))type_tfms = Pipeline([PILImageBW.create])
item_tfms = Pipeline([CropPad((34,34)), CropPad((28,28)), ToTensor()])
batch_tfms = Pipeline([
IntToFloatTensor(),
Normalize.from_stats([[[[0.1302]]]], [[[[0.3081]]]])
])items[0]Path('/home/jovyan/.fastai/data/mnist_png/testing/7/4199.png')im = type_tfms(items[0]); im.shape(28, 28)item_tfms(im).shapetorch.Size([1, 28, 28])batch_tfms(item_tfms(im).cuda()).shapetorch.Size([1, 1, 28, 28])net = learn.model
net.eval()
t_im = batch_tfms(item_tfms(im).cuda())with torch.no_grad():
out = net(t_im)out.argmax(dim=-1)TensorImageBW([7], device='cuda:0')out.softmax(-1)TensorImageBW([[6.1411e-04, 7.0375e-02, 3.8911e-03, 2.9296e-03, 3.8029e-03,
1.0836e-03, 3.5855e-05, 8.9155e-01, 4.3128e-03, 2.1403e-02]],
device='cuda:0')Now what if we wanted to do everything in PyTorch but the training?