graph LR
A{"🤗 Accelerate#32;"}
A --> B["Launching<br>Interface#32;"]
A --> C["Training Library#32;"]
A --> D["Big Model<br>Inference#32;"]
Accelerate, Three Powerful Sublibraries for PyTorch
Zachary Mueller
What is 🤗 Accelerate?
A Launching Interface
Launching scripts in different environments is complicated:
And more!
A Launching Interface
But it doesn’t have to be:
A single command to launch with DeepSpeed, Fully Sharded Data Parallelism, across single and multi CPUs and GPUs, and to train on TPUs1 too!
A Launching Interface
Generate a device-specific configuration through accelerate config
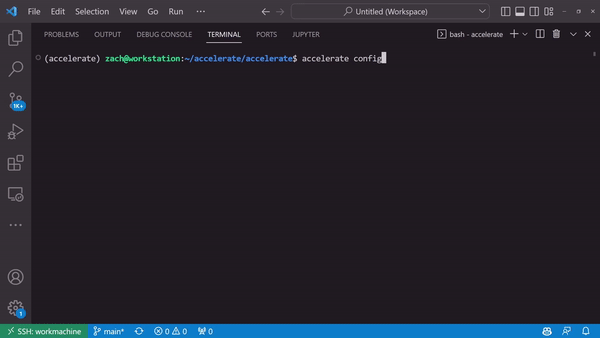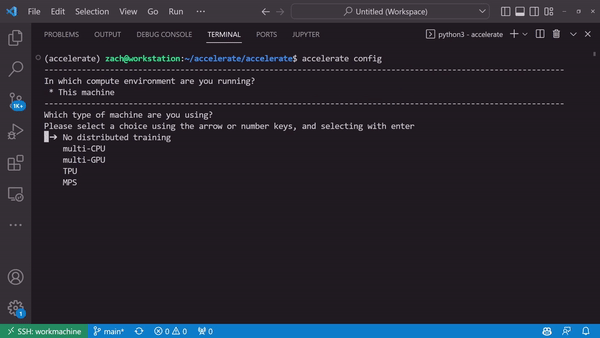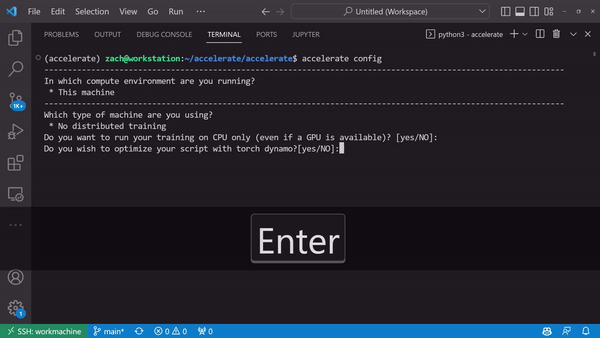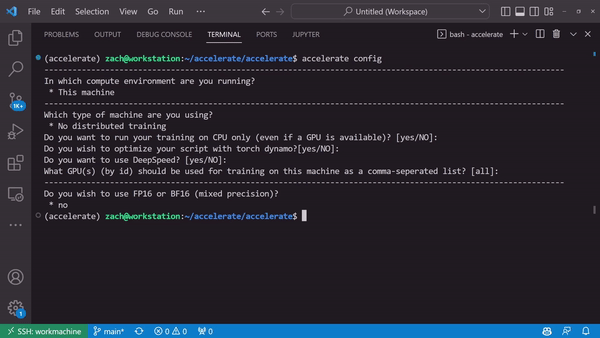
A Launching Interface
Or don’t. accelerate config doesn’t have to be done!
torchrun --nnodes=1 --nproc_per_node=2 script.py
accelerate launch --multi_gpu --nproc_per_node=2 script.pyA quick default configuration can be made too:
A Launching Interface
With the notebook_launcher it’s also possible to launch code directly from your Jupyter environment too!
A Training Library
Okay, will accelerate launch make do_the_thing.py use all my GPUs magically?
A Training Library
- Just showed that its possible using
accelerate launchto launch a python script in various distributed environments - This does not mean that the script will just “use” that code and still run on the new compute efficiently.
- Training on different computes often means many lines of code changed for each specific compute.
- 🤗
acceleratesolves this by ensuring the same code can be ran on a CPU or GPU, multiples, and on TPUs!
A Training Library
A Training Library
from accelerate import Accelerator
accelerator = Accelerator()
dataloader, model, optimizer scheduler = (
accelerator.prepare(
dataloader, model, optimizer, scheduler
)
)
for batch in dataloader:
optimizer.zero_grad()
inputs, targets = batch
# inputs = inputs.to(device)
# targets = targets.to(device)
outputs = model(inputs)
loss = loss_function(outputs, targets)
accelerator.backward(loss) # loss.backward()
optimizer.step()
scheduler.step()A Training Library
What all happened in Accelerator.prepare?
Acceleratorlooked at the configuration- The
dataloaderwas converted into one that can dispatch each batch onto a seperate GPU - The
modelwas wrapped with the appropriate DDP wrapper from eithertorch.distributedortorch_xla - The
optimizerandschedulerwere both converted into anAcceleratedOptimizerandAcceleratedSchedulerwhich knows how to handle any distributed scenario
Let’s bring in fastai
To utilize the notebook_launcher and accelerate at once it requires a few steps:
- Migrate the
DataLoaderscreation to inside thetrainfunction - Use the
distrib_ctxcontext manager fastai provides - Train!
Let’s bring fastai
Here it is in code, based on the distributed app examples
from fastai.vision.all import *
from fastai.distributed import *
path = untar_data(URLs.PETS)/'images'
def train():
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2,
label_func=lambda x: x[0].isupper(), item_tfms=Resize(224))
learn = vision_learner(dls, resnet34, metrics=error_rate).to_fp16()
with learn.distrib_ctx(in_notebook=True, sync_bn=False):
learn.fine_tune(1)
notebook_launcher(train, num_processes=2)Let’s bring fastai
Here it is in code, based on the distributed app examples
from fastai.vision.all import *
from fastai.distributed import *
path = untar_data(URLs.PETS)/'images'
def train():
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2,
label_func=lambda x: x[0].isupper(), item_tfms=Resize(224))
learn = vision_learner(dls, resnet34, metrics=error_rate).to_fp16()
with learn.distrib_ctx(in_notebook=True, sync_bn=False):
learn.fine_tune(1)
notebook_launcher(train, num_processes=2)Let’s bring fastai
The key important parts to remember are:
- No code should touch the GPU before calling
notebook_launcher - Generally it’s recommended to let fastai handle gradient accumulation and mixed precision in this case, so use their in-house Callbacks
- Use the
notebook_launcherto run the training function after everything is complete.